publications
2025
- ACL
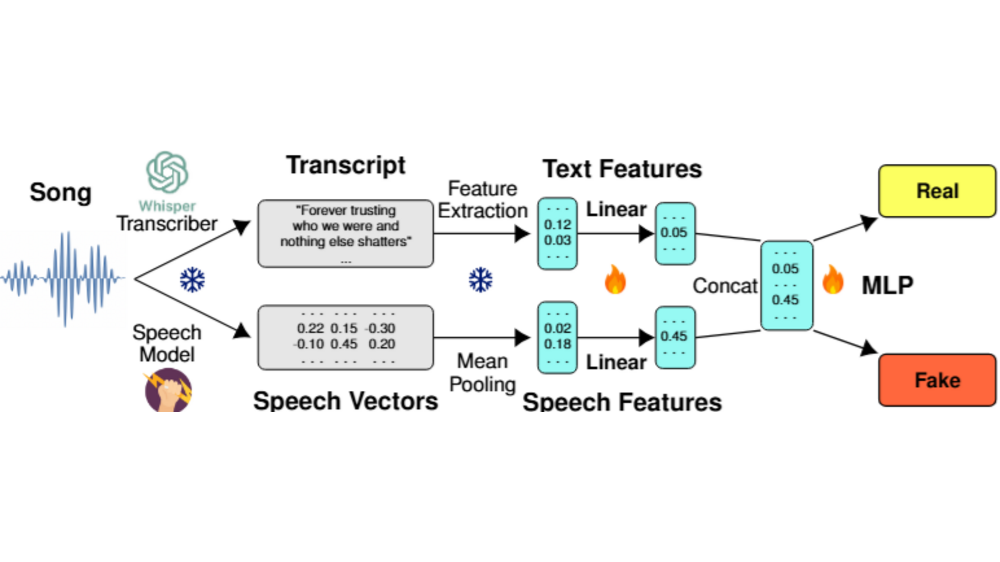 Markus Frohmann, Gabriel Meseguer-Brocal, Markus Schedl, and Elena V. EpureACL 2025 (Findings), Jul 2025
Markus Frohmann, Gabriel Meseguer-Brocal, Markus Schedl, and Elena V. EpureACL 2025 (Findings), Jul 2025The rapid advancement of AI-based music generation tools is revolutionizing the music industry but also posing challenges to artists, copyright holders, and providers alike. This necessitates reliable methods for detecting such AI-generated content. However, existing detectors, relying on either audio or lyrics, face key practical limitations: audio-based detectors fail to generalize to new or unseen generators and are vulnerable to audio perturbations; lyrics-based methods require cleanly formatted and accurate lyrics, unavailable in practice. To overcome these limitations, we propose a novel, practically grounded approach: a multimodal, modular late-fusion pipeline that combines automatically transcribed sung lyrics and speech features capturing lyrics related information within the audio. By relying on lyrical aspects directly from audio, our method enhances robustness, mitigates susceptibility to low-level artifacts, and enables practical applicability. Experiments show that our method, DE-detect, outperforms existing lyrics-based detectors while also being more robust to audio perturbations. Thus, it offers an effective, robust solution for detecting AI-generated music in real-world scenarios. Our code is available at https://github.com/deezer/robust-AI-lyrics-detection.
@inproceedings{frohmann2025double, title = {Double Entendre: Robust Audio-Based {AI}-Generated Lyrics Detection via Multi-View Fusion}, author = {Frohmann, Markus and Meseguer-Brocal, Gabriel and Schedl, Markus and Epure, Elena V.}, editor = {Che, Wanxiang and Nabende, Joyce and Shutova, Ekaterina and Pilehvar, Mohammad Taher}, booktitle = {Findings of the Association for Computational Linguistics: ACL 2025}, month = jul, year = {2025}, address = {Vienna, Austria}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2025.findings-acl.98/}, pages = {1914--1926}, isbn = {979-8-89176-256-5}, } - ISMIR
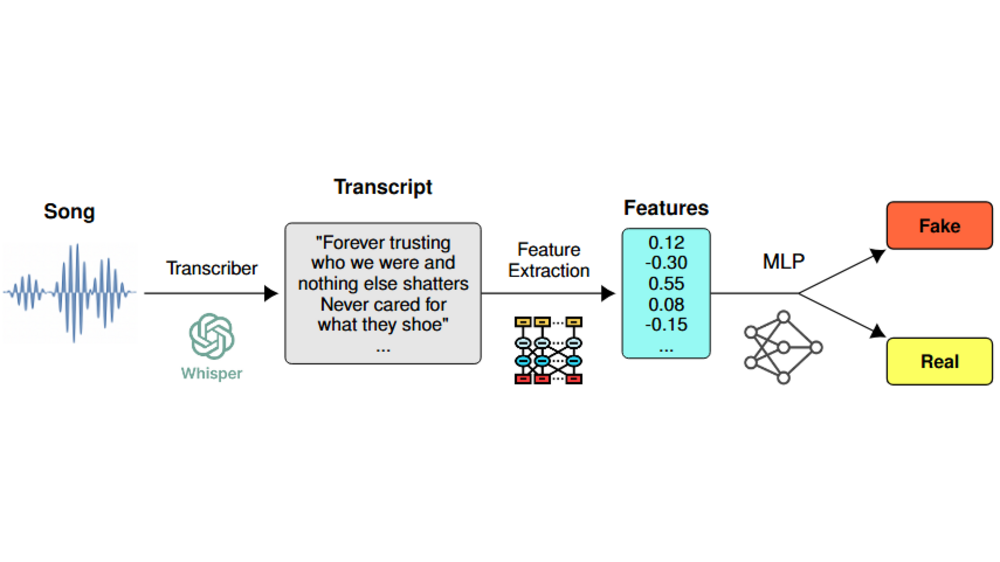 Markus Frohmann, Elena V. Epure, Gabriel Meseguer-Brocal, Markus Schedl, and Romain HennequinISMIR 2025, Jul 2025
Markus Frohmann, Elena V. Epure, Gabriel Meseguer-Brocal, Markus Schedl, and Romain HennequinISMIR 2025, Jul 2025The recent rise in capabilities of AI-based music generation tools has created an upheaval in the music industry, necessitating the creation of accurate methods to detect such AI-generated content. This can be done using audio-based detectors; however, it has been shown that they struggle to generalize to unseen generators or when the audio is perturbed. Furthermore, recent work used accurate and cleanly formatted lyrics sourced from a lyrics provider database to detect AI-generated music. However, in practice, such perfect lyrics are not available (only the audio is); this leaves a substantial gap in applicability in real-life use cases. In this work, we instead propose solving this gap by transcribing songs using general automatic speech recognition (ASR) models. We do this using several detectors. The results on diverse, multi-genre, and multi-lingual lyrics show generally strong detection performance across languages and genres, particularly for our best-performing model using Whisper large-v2 and LLM2Vec embeddings. In addition, we show that our method is more robust than state-of-the-art audio-based ones when the audio is perturbed in different ways and when evaluated on different music generators. Our code is available at https://github.com/deezer/robust-AI-lyrics-detection.
@inproceedings{frohmann2025aidet, title = {AI-Generated Song Detection via Lyrics Transcripts}, author = {Frohmann, Markus and Epure, Elena V. and Meseguer-Brocal, Gabriel and Schedl, Markus and Hennequin, Romain}, booktitle = {Proceedings of the 26th International Society for Music Information Retrieval Conference (ISMIR)}, year = {2025}, address = {Daejeon, South Korea}, publisher = {International Society for Music Information Retrieval}, } - TrustNLP @ NAACL
 Yanis Labrak, Markus Frohmann, Gabriel Meseguer-Brocal, and Elena V. EpureTrustNLP @ NAACL 2025 (Workshop), May 2025
Yanis Labrak, Markus Frohmann, Gabriel Meseguer-Brocal, and Elena V. EpureTrustNLP @ NAACL 2025 (Workshop), May 2025In recent years, the use of large language models (LLMs) to generate music content, particularly lyrics, has gained in popularity. These advances provide valuable tools for artists and enhance their creative processes, but they also raise concerns about copyright violations, consumer satisfaction, and content spamming. Previous research has explored content detection in various domains. However, no work has focused on the text modality, lyrics, in music. To address this gap, we curated a diverse dataset of real and synthetic lyrics from multiple languages, music genres, and artists. The generation pipeline was validated using both humans and automated methods. We performed a thorough evaluation of existing synthetic text detection approaches on lyrics, a previously unexplored data type. We also investigated methods to adapt the best-performing features to lyrics through unsupervised domain adaptation. Following both music and industrial constraints, we examined how well these approaches generalize across languages, scale with data availability, handle multilingual language content, and perform on novel genres in few-shot settings. Our findings show promising results that could inform policy decisions around AI-generated music and enhance transparency for users.
@inproceedings{labrak2025synthetic, title = {Synthetic Lyrics Detection Across Languages and Genres}, author = {Labrak, Yanis and Frohmann, Markus and Meseguer-Brocal, Gabriel and Epure, Elena V.}, editor = {Cao, Trista and Das, Anubrata and Kumarage, Tharindu and Wan, Yixin and Krishna, Satyapriya and Mehrabi, Ninareh and Dhamala, Jwala and Ramakrishna, Anil and Galystan, Aram and Kumar, Anoop and Gupta, Rahul and Chang, Kai-Wei}, booktitle = {Proceedings of the 5th Workshop on Trustworthy NLP (TrustNLP 2025)}, month = may, year = {2025}, address = {Albuquerque, New Mexico}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2025.trustnlp-main.34/}, doi = {10.18653/v1/2025.trustnlp-main.34}, pages = {524--541}, isbn = {979-8-89176-233-6}, } - MICCAI
 Patrick Binder, Marcel Huber, and Markus FrohmannMICCAI 2025 (MARIO Challenge), Apr 2025
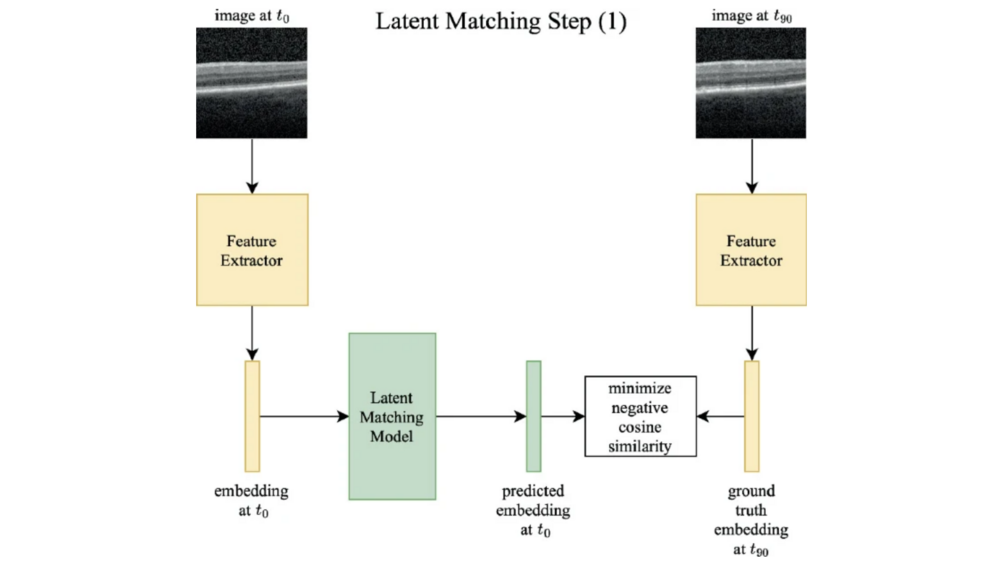
Patrick Binder, Marcel Huber, and Markus FrohmannMICCAI 2025 (MARIO Challenge), Apr 2025Age-related Macular Degeneration (AMD) is the most com-mon cause of severe vision loss in individuals over 50, primarily affecting central vision. In its early stages, AMD often presents no symptoms, making early detection and monitoring its progression essential. Managing AMD effectively requires close observation of neovascular activity, especially its response to anti-VEGF treatments. In this work, we present a predictive model that forecasts AMD progression 90 days in advance using a single Optical Coherence Tomography (OCT) B-scan. Our app-roach leverages advanced deep learning techniques and a novel latent matching model to improve the accuracy of disease state predictions and guide anti-VEGF treatment strategies.
@inproceedings{binder2025mario_task2, title = {jkulinzstudents Submission to the MARIO Challenge 2024: Task 2}, author = {Binder, Patrick and Huber, Marcel and Frohmann, Markus}, booktitle = {Image-Based Prediction of Retinal Disease Progression: MICCAI Challenges, DIAMOND 2024 and MARIO 2024}, series = {LNCS 15503}, pages = {163--171}, address = {Marrakech, Morocco}, publisher = {Springer Nature}, year = {2025}, month = apr, day = {27}, doi = {https://doi.org/10.1007/978-3-031-86651-7_16}, url = {https://dl.acm.org/doi/10.1007/978-3-031-86651-7_16}, } - MICCAI
 Marcel Huber, Patrick Binder, and Markus FrohmannMICCAI 2025 (MARIO Challenge), Apr 2025
Marcel Huber, Patrick Binder, and Markus FrohmannMICCAI 2025 (MARIO Challenge), Apr 2025Age-related Macular Degeneration (AMD) is a leading cause of vision loss in developed countries. The evolution of neovascular activity in AMD, particularly in response to anti-VEGF treatments, is critical for effective management. This paper presents a simple but highly effective method for classifying the evolution between two consecutive Optical Coherence Tomography (OCT) B-scans, focusing on detecting changes indicative of neovascular activity. Our approach leverages state-of-theart deep learning techniques, namely transfer learning of the DinoV2 model with extensive data augmentations, to improve the planning of individualized anti-VEGF treatment strategies. It achieves an F1 score of 0.83 on the public leaderboard of task 1 of the MARIO challenge.
@inproceedings{huber2025mario_task1, title = {jkulinzstudents Submission to the MARIO Challenge 2024: Task 1}, author = {Huber, Marcel and Binder, Patrick and Frohmann, Markus}, booktitle = {Image-Based Prediction of Retinal Disease Progression: MICCAI Challenges, DIAMOND 2024 and MARIO 2024}, series = {LNCS 15503}, publisher = {Springer Nature}, address = {Marrakech, Morocco}, pages = {15--162}, year = {2025}, month = apr, day = {27}, doi = {https://doi.org/10.1007/978-3-031-86651-7_15}, url = {https://dl.acm.org/doi/10.1007/978-3-031-86651-7_15}, }
2024
- EMNLP
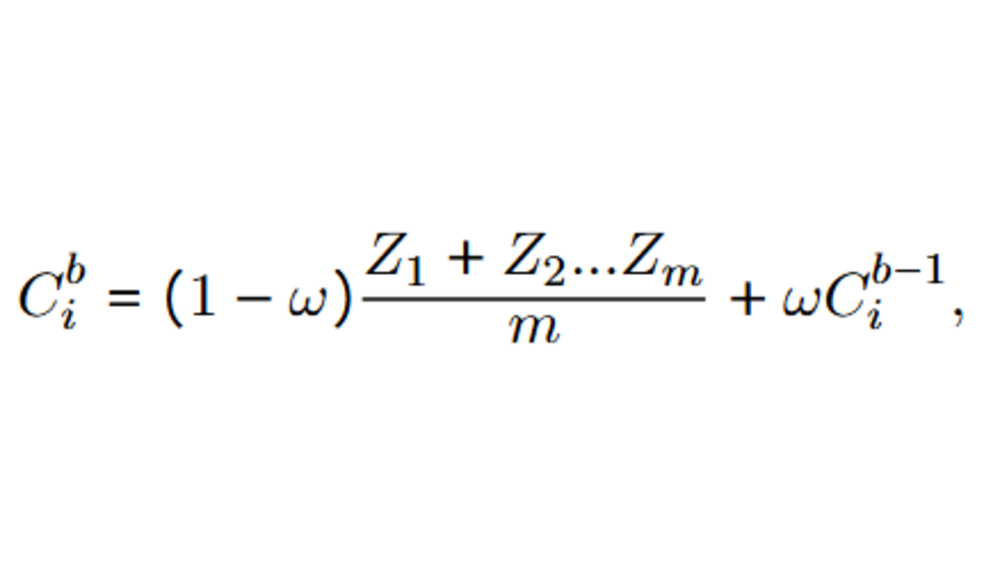 Shahed Masoudian, Markus Frohmann, Navid Rekabsaz, and Markus SchedlEMNLP 2024 (Main Conference), Nov 2024
Shahed Masoudian, Markus Frohmann, Navid Rekabsaz, and Markus SchedlEMNLP 2024 (Main Conference), Nov 2024Language models frequently inherit societal biases from their training data. Numerous techniques have been proposed to mitigate these biases during both the pre-training and fine-tuning stages. However, fine-tuning a pre-trained debiased language model on a downstream task can reintroduce biases into the model. Additionally, existing debiasing methods for downstream tasks either (i) require labels of protected attributes (e.g., age, race, or political views) that are often not available or (ii) rely on indicators of bias, which restricts their applicability to gender debiasing since they rely on gender-specific words. To address this, we introduce a novel debiasing regularization technique based on the class-wise variance of embeddings. Crucially, our method does not require attribute labels and targets any attribute, thus addressing the shortcomings of existing debiasing methods. Our experiments on encoder language models and three datasets demonstrate that our method outperforms existing strong debiasing baselines that rely on target attribute labels while maintaining performance on the target task.
@inproceedings{masoudian2024unlabeled, title = {Unlabeled Debiasing in Downstream Tasks via Class-wise Low Variance Regularization}, author = {Masoudian, Shahed and Frohmann, Markus and Rekabsaz, Navid and Schedl, Markus}, editor = {Al-Onaizan, Yaser and Bansal, Mohit and Chen, Yun-Nung}, booktitle = {Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing}, month = nov, year = {2024}, address = {Miami, Florida, USA}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.emnlp-main.612/}, doi = {10.18653/v1/2024.emnlp-main.612}, pages = {10932--10938}, } - EMNLP
 Markus Frohmann, Igor Sterner, Ivan Vulić, Benjamin Minixhofer, and Markus SchedlEMNLP 2024 (Main Conference), Nov 2024
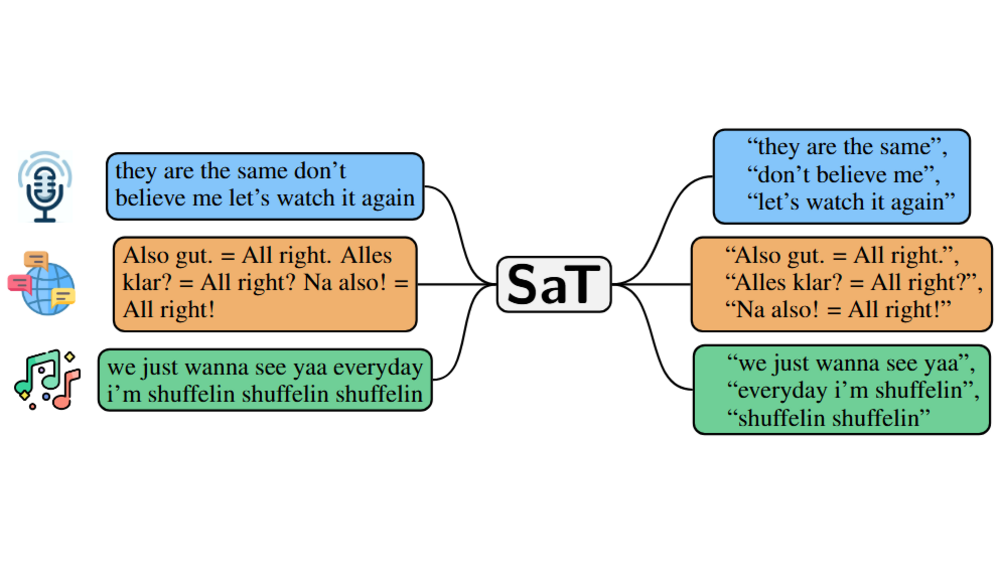
Markus Frohmann, Igor Sterner, Ivan Vulić, Benjamin Minixhofer, and Markus SchedlEMNLP 2024 (Main Conference), Nov 2024Segmenting text into sentences plays an early and crucial role in many NLP systems. This is commonly achieved by using rule-based or statistical methods relying on lexical features such as punctuation. Although some recent works no longer exclusively rely on punctuation, we find that no prior method achieves all of (i) robustness to missing punctuation, (ii) effective adaptability to new domains, and (iii) high efficiency. We introduce a new model — Segment any Text (SaT) — to solve this problem. To enhance robustness, we propose a new pretraining scheme that ensures less reliance on punctuation. To address adaptability, we introduce an extra stage of parameter-efficient fine-tuning, establishing state-of-the-art performance in distinct domains such as verses from lyrics and legal documents. Along the way, we introduce architectural modifications that result in a threefold gain in speed over the previous state of the art and solve spurious reliance on context far in the future. Finally, we introduce a variant of our model with fine-tuning on a diverse, multilingual mixture of sentence-segmented data, acting as a drop-in replacement and enhancement for existing segmentation tools. Overall, our contributions provide a universal approach for segmenting any text. Our method outperforms all baselines — including strong LLMs — across 8 corpora spanning diverse domains and languages, especially in practically relevant situations where text is poorly formatted. Our models and code, including documentation, are readily available at https://github.com/segment-any-text/wtpsplit under the MIT license.
@inproceedings{frohmann2024segment, title = {Segment Any Text: A Universal Approach for Robust, Efficient and Adaptable Sentence Segmentation}, author = {Frohmann, Markus and Sterner, Igor and Vuli{\'c}, Ivan and Minixhofer, Benjamin and Schedl, Markus}, editor = {Al-Onaizan, Yaser and Bansal, Mohit and Chen, Yun-Nung}, booktitle = {Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing}, month = nov, year = {2024}, address = {Miami, Florida, USA}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.emnlp-main.665/}, doi = {10.18653/v1/2024.emnlp-main.665}, pages = {11908--11941}, } - ACL
 Markus Frohmann, Carolin Holtermann, Shahed Masoudian, Anne Lauscher, and Navid RekabsazACL 2024 (Findings), Aug 2024
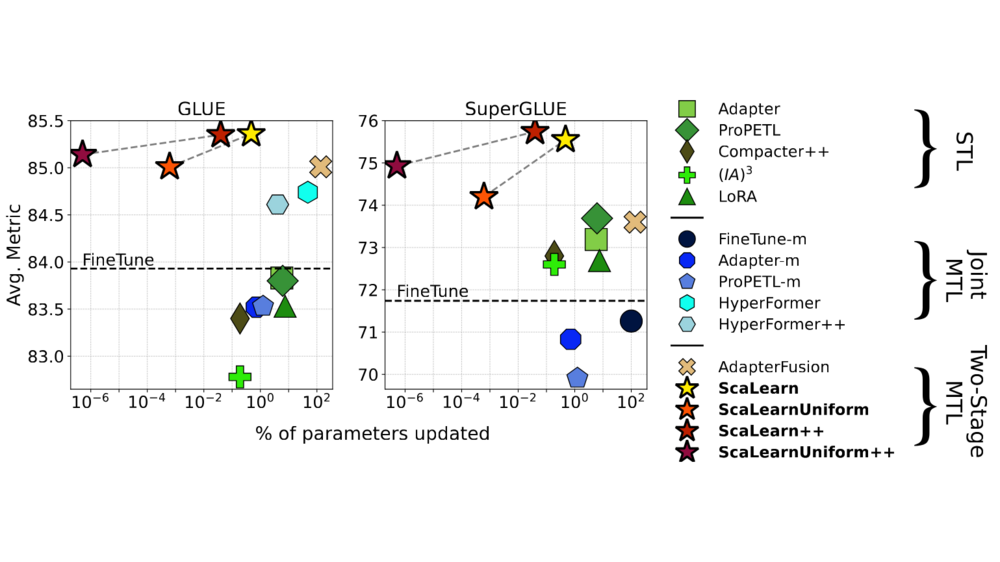
Markus Frohmann, Carolin Holtermann, Shahed Masoudian, Anne Lauscher, and Navid RekabsazACL 2024 (Findings), Aug 2024Multi-task learning (MTL) has shown considerable practical benefits, particularly when using language models (LMs). While this is commonly achieved by learning tasks under a joint optimization procedure, some methods, such as AdapterFusion, divide the problem into two stages: (i) task learning, where knowledge specific to a task is encapsulated within sets of parameters (e.g., adapters), and (ii) transfer, where this already learned knowledge is leveraged for a target task. This separation of concerns provides numerous benefits (e.g., promoting reusability). However, current two stage MTL introduces a substantial number of additional parameters. We address this issue by leveraging the usefulness of linearly scaling the output representations of source adapters for transfer learning. We introduce ScaLearn, a simple and highly parameter-efficient two-stage MTL method that capitalizes on the knowledge of the source tasks by learning a minimal set of scaling parameters that enable effective transfer to a target task. Our experiments on three benchmarks (GLUE, SuperGLUE, and HumSet) and two encoder LMs show that ScaLearn consistently outperforms strong baselines with a small number of transfer parameters (~0.35% of those of AdapterFusion). Remarkably, we observe that ScaLearn maintains its strong abilities even when further reducing parameters, achieving competitive results with only 8 transfer parameters per target task. Our proposed approach thus demonstrates the power of simple scaling as a promise for more efficient task transfer. Our code is available at https://github.com/CPJKU/ScaLearn.
@inproceedings{frohmann2024scalearn, title = {{S}ca{L}earn: Simple and Highly Parameter-Efficient Task Transfer by Learning to Scale}, author = {Frohmann, Markus and Holtermann, Carolin and Masoudian, Shahed and Lauscher, Anne and Rekabsaz, Navid}, editor = {Ku, Lun-Wei and Martins, Andre and Srikumar, Vivek}, booktitle = {Findings of the Association for Computational Linguistics: ACL 2024}, month = aug, year = {2024}, address = {Bangkok, Thailand}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.findings-acl.699/}, doi = {10.18653/v1/2024.findings-acl.699}, pages = {11743--11776}, } - EACL
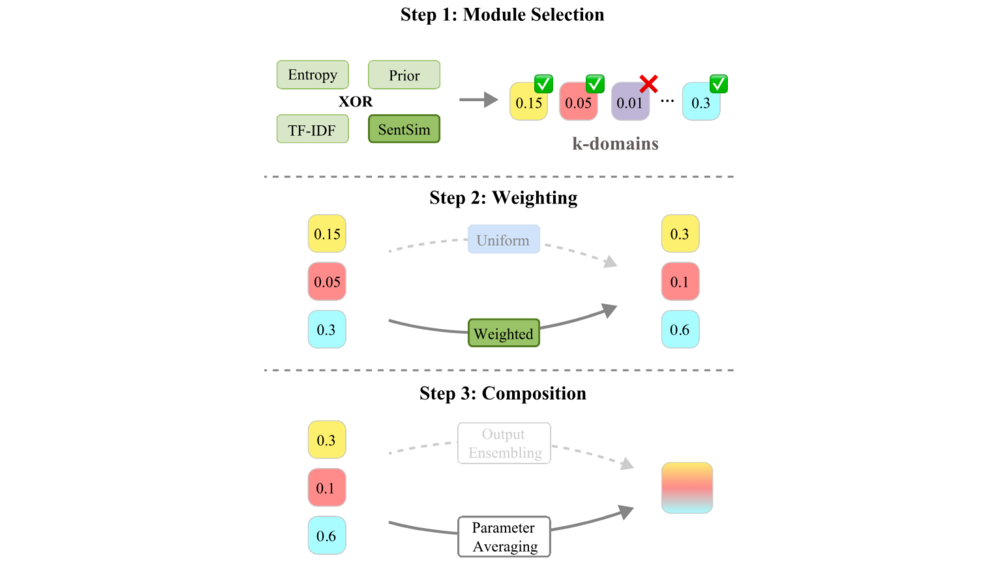 Carolin Holtermann, Markus Frohmann, Navid Rekabsaz, and Anne LauscherEACL 2024 (Findings), Mar 2024
Carolin Holtermann, Markus Frohmann, Navid Rekabsaz, and Anne LauscherEACL 2024 (Findings), Mar 2024The knowledge encapsulated in a model is the core factor determining its final performance on downstream tasks. Much research in NLP has focused on efficient methods for storing and adapting different types of knowledge, e.g., in dedicated modularized structures, and on how to effectively combine these, e.g., by learning additional parameters. However, given the many possible options, a thorough understanding of the mechanisms involved in these compositions is missing, and hence it remains unclear which strategies to utilize. To address this research gap, we propose a novel framework for zero-shot module composition, which encompasses existing and some novel variations for selecting, weighting, and combining parameter modules under a single unified notion. Focusing on the scenario of domain knowledge and adapter layers, our framework provides a systematic unification of concepts, allowing us to conduct the first comprehensive benchmarking study of various zero-shot knowledge composition strategies. In particular, we test two module combination methods and five selection and weighting strategies for their effectiveness and efficiency in an extensive experimental setup. Our results highlight the efficacy of ensembling but also hint at the power of simple though often-ignored weighting methods. Further in-depth analyses allow us to understand the role of weighting vs. top-k selection, and show that, to a certain extent, the performance of adapter composition can even be predicted.
@inproceedings{holtermann2024weight, title = {What the Weight?! A Unified Framework for Zero-Shot Knowledge Composition}, author = {Holtermann, Carolin and Frohmann, Markus and Rekabsaz, Navid and Lauscher, Anne}, editor = {Graham, Yvette and Purver, Matthew}, booktitle = {Findings of the Association for Computational Linguistics: EACL 2024}, month = mar, year = {2024}, address = {St. Julian{'}s, Malta}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.findings-eacl.77/}, pages = {1138--1157}, }
2023
- BDCC
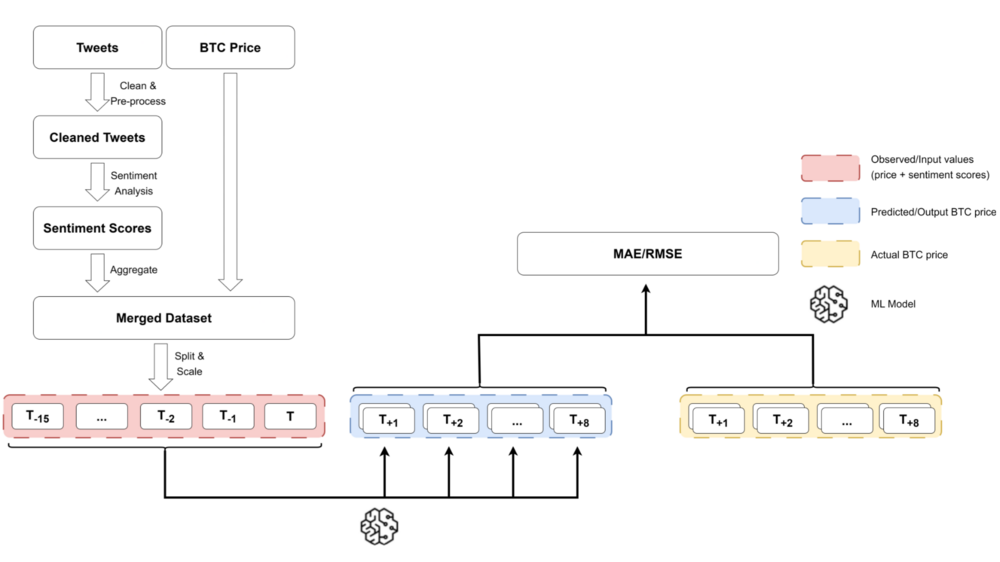 Markus Frohmann, Mario Karner, Said Khudoyan, Robert Wagner, and Markus SchedlBig Data and Cognitive Computing, Mar 2023
Markus Frohmann, Mario Karner, Said Khudoyan, Robert Wagner, and Markus SchedlBig Data and Cognitive Computing, Mar 2023Recently, various methods to predict the future price of financial assets have emerged. One promising approach is to combine the historic price with sentiment scores derived via sentiment analysis techniques. In this article, we focus on predicting the future price of Bitcoin, which is currently the most popular cryptocurrency. More precisely, we propose a hybrid approach, combining time series forecasting and sentiment prediction from microblogs, to predict the intraday price of Bitcoin. Moreover, in addition to standard sentiment analysis methods, we are the first to employ a fine-tuned BERT model for this task. We also introduce a novel weighting scheme in which the weight of the sentiment of each tweet depends on the number of its creator’s followers. For evaluation, we consider periods with strongly varying ranges of Bitcoin prices. This enables us to assess the models w.r.t. robustness and generalization to varied market conditions. Our experiments demonstrate that BERT-based sentiment analysis and the proposed weighting scheme improve upon previous methods. Specifically, our hybrid models that use linear regression as the underlying forecasting algorithm perform best in terms of the mean absolute error (MAE of 2.67) and root mean squared error (RMSE of 3.28). However, more complicated models, particularly long short-term memory networks and temporal convolutional networks, tend to have generalization and overfitting issues, resulting in considerably higher MAE and RMSE scores.
@article{frohmann2023predicting, title = {Predicting the Price of Bitcoin Using Sentiment-Enriched Time Series Forecasting}, author = {Frohmann, Markus and Karner, Mario and Khudoyan, Said and Wagner, Robert and Schedl, Markus}, journal = {Big Data and Cognitive Computing}, volume = {7}, number = {3}, pages = {137}, year = {2023}, publisher = {MDPI}, issn = {2504-2289}, url = {https://www.mdpi.com/2504-2289/7/3/137}, doi = {10.3390/bdcc7030137}, }